
The Challenge
Pivotree had a client who wanted to autoscale ATG application servers under certain conditions. The challenge was that previously servers were provisioned and built up based on requirements and were static. Server configurations were baked into the EAR and called using JVM args. Any platform integration was all done manually and it could take several days to weeks to complete a build-out.
The client had been previously migrated to AWS cloud but at the time it was a basic lift and shift with the environment deployed using terraform and then built and managed manually. Common patterns/tooling/processes from the data center were also migrated over. This was based on the client’s requirements at the time.
The ATG application consists of several layers. The client-facing application servers are commonly referred to as page or com servers, the content management system called BCC which typically is configured manually to register the various application servers and publish/update content as required, and the Endeca search engine which also requires manually updating various configuration files to add/remove application servers from the configuration.
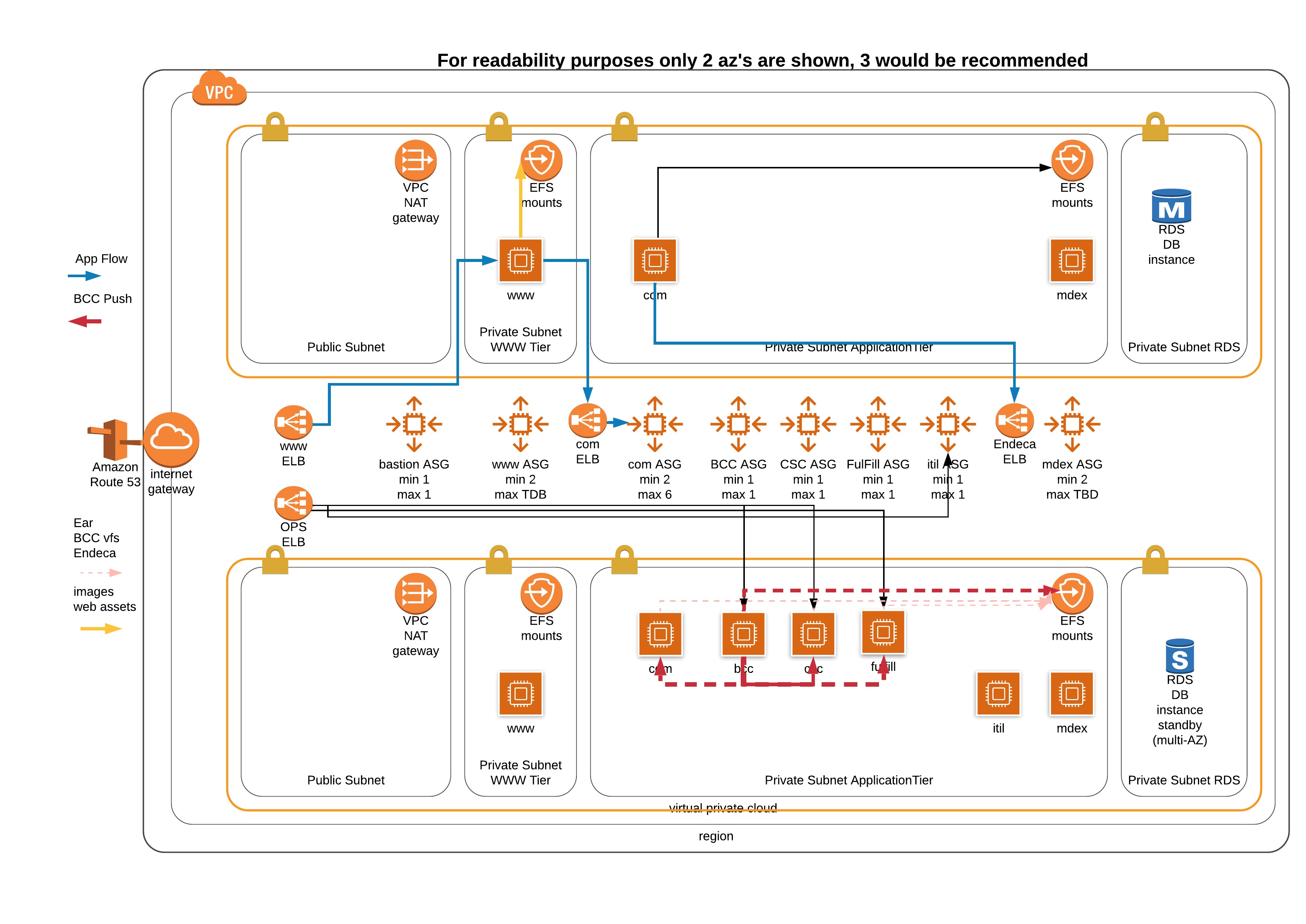
Several things had to be considered when developing this solution. How we were going to build the images, how we were going to store the runtime parameters, update the various configuration files, start the application and register the application servers with BCC and Endeca servers.
Additional consideration around centralized logging, user access, and troubleshooting was also a factor. Our SI and OP teams were used to having ssh to all boxes, finding logs on the boxes, and resolving issues on the boxes. PCI requirements were also a factor as we needed to be sure we were developing a solution we could certify at a later date.
On Building Immutable Infrastructure
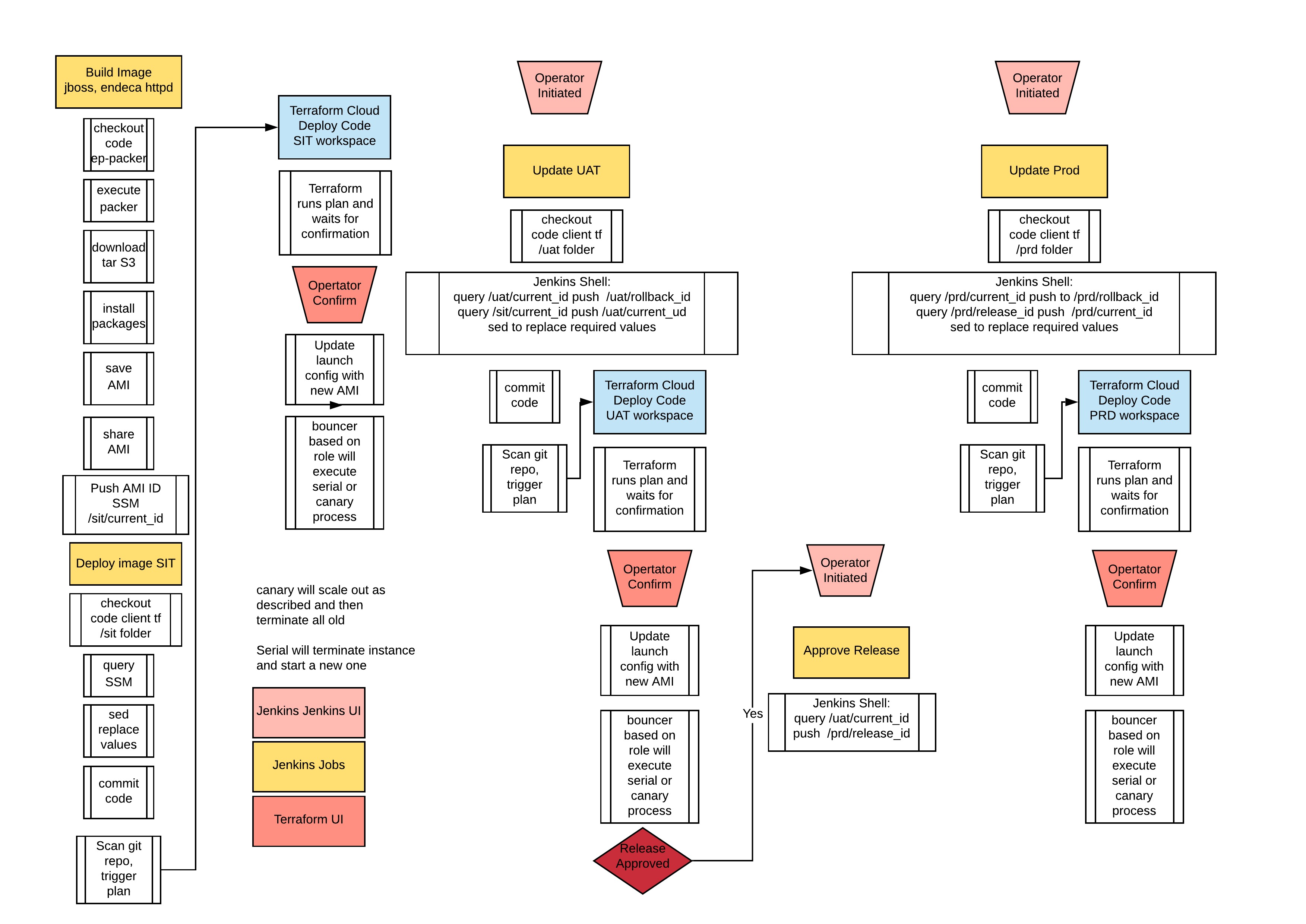
After a careful analysis of the software stack and previous knowledge working with the platform, it was decided we would need to create immutable images. Using an immutable image meant we could use the same image across environments as well as potentially re-use this solution in the future with additional clients. We were already working with Hashicorp Packer in other parts of the organization and it was a natural fit for what we planned on building.
During the development of the solution, we also decided that we would leverage the AWS System Manager Parameter Store to hold all the runtime values required. We developed a hierarchy that we could use to ensure each environment’s values were separated based on the hierarchical path. As part of this, a process was developed to update a “property” file that was then parsed and pushed into SSM.
Due to the size of some of the software we install and the need for autoscaling to occur rapidly another key decision was separating the building of images and loading of runtime values. Working with Packer we built 2 machine images. One for the application stack based on Java and Jboss 7.2, the other for Endeca based on Endeca 11.3.2. We also started developing various scripts to populate our configuration and startup files.
We determined early in the process that we would leverage AWS resource tags to determine what environment we were working on as well as the role of the server. Using those tags allowed us to make decisions and build our queries to SSM. We also decided that we would have 1 download.sh script in our user folder which would be called via cloud-init and would then query tags and download the appropriate automation package from an S3 bucket we had. This gave us the flexibility to update those scripts/templates without requiring a new image.
Both images required the mounting of efs volumes so we developed a script to query SSM for the EFS endpoints, update our template and then append the file to fstab and remount everything. The Endeca image was fairly basic with a few installations completed using silent install options and required scripts copied into the home folder.
Once we had completed the Endeca image the next step was to figure out every value we edit in the JBoss configuration files and start replacing those with a token. We also developed a script that would query SSM for that required value and then replace the token with the updated value. This allowed for different configurations such as Datasource URL, Datasource username, or passwords to be unique across env as it would get loaded at runtime.
JTNDZGl2JTIwY2xhc3MlM0QlMjJoaWdobGlnaHQlMjIlM0UlM0NwcmUlMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzZjhmOGYyJTNCYmFja2dyb3VuZC1jb2xvciUzQSUyMzI3MjgyMiUzQi1tb3otdGFiLXNpemUlM0E0JTNCLW8tdGFiLXNpemUlM0E0JTNCdGFiLXNpemUlM0E0JTIyJTNFJTNDY29kZSUyMGNsYXNzJTNEJTIybGFuZ3VhZ2UtYmFzaCUyMiUyMGRhdGEtbGFuZyUzRCUyMmJhc2glMjIlMjBzdHlsZSUzRCUyMmJvcmRlciUzQSUyMG5vbmUlMjAlMjFpbXBvcnRhbnQlM0IlMjIlM0UlMEElM0NzcGFuJTIwc3R5bGUlM0QlMjJjb2xvciUzQSUyMzc1NzE1ZSUyMiUzRSUyMyUyMyUyMyUyMyUyMyUzQyUyRnNwYW4lM0UlMEElM0NzcGFuJTIwc3R5bGUlM0QlMjJjb2xvciUzQSUyMzc1NzE1ZSUyMiUzRSUyMyUyMyUyMyUyMyUyMyUyMFF1ZXJ5JTIwU1NNJTIwYW5kJTIwYXNzaWduJTIwdG8lMjB2YXJpYWJsZXMlM0MlMkZzcGFuJTNFJTBBJTNDc3BhbiUyMHN0eWxlJTNEJTIyY29sb3IlM0ElMjM3NTcxNWUlMjIlM0UlMjMlMjMlMjMlMjMlMjMlM0MlMkZzcGFuJTNFJTBBJTBBcmRzX3VybCUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzZjkyNjcyJTIyJTNFJTNEJTNDJTJGc3BhbiUzRSUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzNjZkOWVmJTIyJTNFJTI0JTI4JTNDJTJGc3BhbiUzRWF3cyUyMHNzbSUyMC0tcmVnaW9uJTIwJTNDc3BhbiUyMHN0eWxlJTNEJTIyY29sb3IlM0ElMjM2NmQ5ZWYlMjIlM0UlMjQlMjglM0MlMkZzcGFuJTNFY3VybCUyMC1zJTIwaHR0cCUzQSUyRiUyRjE2OS4yNTQuMTY5LjI1NCUyRmxhdGVzdCUyRm1ldGEtZGF0YSUyRnBsYWNlbWVudCUyRmF2YWlsYWJpbGl0eS16b25lJTIwJTdDJTIwc2VkJTIwLWUlMjAlM0NzcGFuJTIwc3R5bGUlM0QlMjJjb2xvciUzQSUyM2U2ZGI3NCUyMiUzRSUyMnMlMkYuJTNDJTJGc3BhbiUzRSUyNCUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzZTZkYjc0JTIyJTNFJTJGJTJGJTIyJTNDJTJGc3BhbiUzRSUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzNjZkOWVmJTIyJTNFJTI5JTNDJTJGc3BhbiUzRSUyMCUyMCUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzYWU4MWZmJTIyJTNFJTVDJTBBJTNDJTJGc3BhbiUzRSUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzYWU4MWZmJTIyJTNFJTNDJTJGc3BhbiUzRWdldC1wYXJhbWV0ZXJzJTIwLS1uYW1lcyUyMCUyRiUyNGVudiUyRnJkcyUyRnJkc191cmwlMjAtLXF1ZXJ5JTIwJTNDc3BhbiUyMHN0eWxlJTNEJTIyY29sb3IlM0ElMjNlNmRiNzQlMjIlM0UlMjJQYXJhbWV0ZXJzJTVCJTJBJTVELiU3QlZhbHVlJTNBVmFsdWUlN0QlMjIlM0MlMkZzcGFuJTNFJTIwJTdDJTIwZ3JlcCUyMFZhbHVlJTIwJTdDJTIwY3V0JTIwLWQlM0NzcGFuJTIwc3R5bGUlM0QlMjJjb2xvciUzQSUyM2U2ZGI3NCUyMiUzRSUyNyUyMiUyNyUzQyUyRnNwYW4lM0UlMjAtZjQlM0NzcGFuJTIwc3R5bGUlM0QlMjJjb2xvciUzQSUyMzY2ZDllZiUyMiUzRSUyOSUzQyUyRnNwYW4lM0UlMEElMEFyZHMyX3VybCUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzZjkyNjcyJTIyJTNFJTNEJTNDJTJGc3BhbiUzRSUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzNjZkOWVmJTIyJTNFJTI0JTI4JTNDJTJGc3BhbiUzRWF3cyUyMHNzbSUyMC0tcmVnaW9uJTIwJTNDc3BhbiUyMHN0eWxlJTNEJTIyY29sb3IlM0ElMjM2NmQ5ZWYlMjIlM0UlMjQlMjglM0MlMkZzcGFuJTNFY3VybCUyMC1zJTIwaHR0cCUzQSUyRiUyRjE2OS4yNTQuMTY5LjI1NCUyRmxhdGVzdCUyRm1ldGEtZGF0YSUyRnBsYWNlbWVudCUyRmF2YWlsYWJpbGl0eS16b25lJTIwJTdDJTIwc2VkJTIwLWUlMjAlM0NzcGFuJTIwc3R5bGUlM0QlMjJjb2xvciUzQSUyM2U2ZGI3NCUyMiUzRSUyMnMlMkYuJTNDJTJGc3BhbiUzRSUyNCUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzZTZkYjc0JTIyJTNFJTJGJTJGJTIyJTNDJTJGc3BhbiUzRSUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzNjZkOWVmJTIyJTNFJTI5JTNDJTJGc3BhbiUzRSUyMCUyMCUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzYWU4MWZmJTIyJTNFJTVDJTBBJTNDJTJGc3BhbiUzRSUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzYWU4MWZmJTIyJTNFJTNDJTJGc3BhbiUzRWdldC1wYXJhbWV0ZXJzJTIwLS1uYW1lcyUyMCUyRiUyNGVudiUyRnJkcyUyRnJkczJfdXJsJTIwLS1xdWVyeSUyMCUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzZTZkYjc0JTIyJTNFJTIyUGFyYW1ldGVycyU1QiUyQSU1RC4lN0JWYWx1ZSUzQVZhbHVlJTdEJTIyJTNDJTJGc3BhbiUzRSUyMCU3QyUyMGdyZXAlMjBWYWx1ZSUyMCU3QyUyMGN1dCUyMC1kJTNDc3BhbiUyMHN0eWxlJTNEJTIyY29sb3IlM0ElMjNlNmRiNzQlMjIlM0UlMjclMjIlMjclM0MlMkZzcGFuJTNFJTIwLWY0JTNDc3BhbiUyMHN0eWxlJTNEJTIyY29sb3IlM0ElMjM2NmQ5ZWYlMjIlM0UlMjklM0MlMkZzcGFuJTNFJTBBJTBBJTBBcmRzX2RiX25hbWUlM0NzcGFuJTIwc3R5bGUlM0QlMjJjb2xvciUzQSUyM2Y5MjY3MiUyMiUzRSUzRCUzQyUyRnNwYW4lM0UlM0NzcGFuJTIwc3R5bGUlM0QlMjJjb2xvciUzQSUyMzY2ZDllZiUyMiUzRSUyNCUyOCUzQyUyRnNwYW4lM0Vhd3MlMjBzc20lMjAtLXJlZ2lvbiUyMCUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzNjZkOWVmJTIyJTNFJTI0JTI4JTNDJTJGc3BhbiUzRWN1cmwlMjAtcyUyMGh0dHAlM0ElMkYlMkYxNjkuMjU0LjE2OS4yNTQlMkZsYXRlc3QlMkZtZXRhLWRhdGElMkZwbGFjZW1lbnQlMkZhdmFpbGFiaWxpdHktem9uZSUyMCU3QyUyMHNlZCUyMC1lJTIwJTNDc3BhbiUyMHN0eWxlJTNEJTIyY29sb3IlM0ElMjNlNmRiNzQlMjIlM0UlMjJzJTJGLiUzQyUyRnNwYW4lM0UlMjQlM0NzcGFuJTIwc3R5bGUlM0QlMjJjb2xvciUzQSUyM2U2ZGI3NCUyMiUzRSUyRiUyRiUyMiUzQyUyRnNwYW4lM0UlM0NzcGFuJTIwc3R5bGUlM0QlMjJjb2xvciUzQSUyMzY2ZDllZiUyMiUzRSUyOSUzQyUyRnNwYW4lM0UlMjAlMjAlM0NzcGFuJTIwc3R5bGUlM0QlMjJjb2xvciUzQSUyM2FlODFmZiUyMiUzRSU1QyUwQSUzQyUyRnNwYW4lM0UlM0NzcGFuJTIwc3R5bGUlM0QlMjJjb2xvciUzQSUyM2FlODFmZiUyMiUzRSUzQyUyRnNwYW4lM0VnZXQtcGFyYW1ldGVycyUyMC0tbmFtZXMlMjByZHNfZGJfbmFtZSUyMC0tcXVlcnklMjAlM0NzcGFuJTIwc3R5bGUlM0QlMjJjb2xvciUzQSUyM2U2ZGI3NCUyMiUzRSUyMlBhcmFtZXRlcnMlNUIlMkElNUQuJTdCVmFsdWUlM0FWYWx1ZSU3RCUyMiUzQyUyRnNwYW4lM0UlMjAlN0MlMjBncmVwJTIwVmFsdWUlMjAlN0MlMjBjdXQlMjAtZCUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzZTZkYjc0JTIyJTNFJTI3JTIyJTI3JTNDJTJGc3BhbiUzRSUyMC1mNCUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzNjZkOWVmJTIyJTNFJTI5JTNDJTJGc3BhbiUzRSUwQSUwQXJkc19jb3JlX3VzZXJuYW1lJTNDc3BhbiUyMHN0eWxlJTNEJTIyY29sb3IlM0ElMjNmOTI2NzIlMjIlM0UlM0QlM0MlMkZzcGFuJTNFJTNDc3BhbiUyMHN0eWxlJTNEJTIyY29sb3IlM0ElMjM2NmQ5ZWYlMjIlM0UlMjQlMjglM0MlMkZzcGFuJTNFYXdzJTIwc3NtJTIwLS1yZWdpb24lMjAlM0NzcGFuJTIwc3R5bGUlM0QlMjJjb2xvciUzQSUyMzY2ZDllZiUyMiUzRSUyNCUyOCUzQyUyRnNwYW4lM0VjdXJsJTIwLXMlMjBodHRwJTNBJTJGJTJGMTY5LjI1NC4xNjkuMjU0JTJGbGF0ZXN0JTJGbWV0YS1kYXRhJTJGcGxhY2VtZW50JTJGYXZhaWxhYmlsaXR5LXpvbmUlMjAlN0MlMjBzZWQlMjAtZSUyMCUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzZTZkYjc0JTIyJTNFJTIycyUyRi4lM0MlMkZzcGFuJTNFJTI0JTNDc3BhbiUyMHN0eWxlJTNEJTIyY29sb3IlM0ElMjNlNmRiNzQlMjIlM0UlMkYlMkYlMjIlM0MlMkZzcGFuJTNFJTNDc3BhbiUyMHN0eWxlJTNEJTIyY29sb3IlM0ElMjM2NmQ5ZWYlMjIlM0UlMjklM0MlMkZzcGFuJTNFJTIwJTIwJTNDc3BhbiUyMHN0eWxlJTNEJTIyY29sb3IlM0ElMjNhZTgxZmYlMjIlM0UlNUMlMEElM0MlMkZzcGFuJTNFJTNDc3BhbiUyMHN0eWxlJTNEJTIyY29sb3IlM0ElMjNhZTgxZmYlMjIlM0UlM0MlMkZzcGFuJTNFZ2V0LXBhcmFtZXRlcnMlMjAtLW5hbWVzJTIwJTJGJTI0ZW52JTJGY29yZSUyRnVzZXJuYW1lJTIwLS1xdWVyeSUyMCUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzZTZkYjc0JTIyJTNFJTIyUGFyYW1ldGVycyU1QiUyQSU1RC4lN0JWYWx1ZSUzQVZhbHVlJTdEJTIyJTNDJTJGc3BhbiUzRSUyMCU3QyUyMGdyZXAlMjBWYWx1ZSUyMCU3QyUyMGN1dCUyMC1kJTNDc3BhbiUyMHN0eWxlJTNEJTIyY29sb3IlM0ElMjNlNmRiNzQlMjIlM0UlMjclMjIlMjclM0MlMkZzcGFuJTNFJTIwLWY0JTNDc3BhbiUyMHN0eWxlJTNEJTIyY29sb3IlM0ElMjM2NmQ5ZWYlMjIlM0UlMjklM0MlMkZzcGFuJTNFJTBBJTBBcmRzX2NvcmVfcGFzc3dvcmQlM0NzcGFuJTIwc3R5bGUlM0QlMjJjb2xvciUzQSUyM2Y5MjY3MiUyMiUzRSUzRCUzQyUyRnNwYW4lM0UlM0NzcGFuJTIwc3R5bGUlM0QlMjJjb2xvciUzQSUyMzY2ZDllZiUyMiUzRSUyNCUyOCUzQyUyRnNwYW4lM0Vhd3MlMjBzc20lMjAtLXJlZ2lvbiUyMCUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzNjZkOWVmJTIyJTNFJTI0JTI4JTNDJTJGc3BhbiUzRWN1cmwlMjAtcyUyMGh0dHAlM0ElMkYlMkYxNjkuMjU0LjE2OS4yNTQlMkZsYXRlc3QlMkZtZXRhLWRhdGElMkZwbGFjZW1lbnQlMkZhdmFpbGFiaWxpdHktem9uZSUyMCU3QyUyMHNlZCUyMC1lJTIwJTNDc3BhbiUyMHN0eWxlJTNEJTIyY29sb3IlM0ElMjNlNmRiNzQlMjIlM0UlMjJzJTJGLiUzQyUyRnNwYW4lM0UlMjQlM0NzcGFuJTIwc3R5bGUlM0QlMjJjb2xvciUzQSUyM2U2ZGI3NCUyMiUzRSUyRiUyRiUyMiUzQyUyRnNwYW4lM0UlM0NzcGFuJTIwc3R5bGUlM0QlMjJjb2xvciUzQSUyMzY2ZDllZiUyMiUzRSUyOSUzQyUyRnNwYW4lM0UlMjAlMjAlM0NzcGFuJTIwc3R5bGUlM0QlMjJjb2xvciUzQSUyM2FlODFmZiUyMiUzRSU1QyUwQSUzQyUyRnNwYW4lM0UlM0NzcGFuJTIwc3R5bGUlM0QlMjJjb2xvciUzQSUyM2FlODFmZiUyMiUzRSUzQyUyRnNwYW4lM0VnZXQtcGFyYW1ldGVycyUyMC0tbmFtZXMlMjAlMkYlMjRlbnYlMkZjb3JlJTJGcGFzc3dvcmQlMjAtLXdpdGgtZGVjcnlwdGlvbiUyMC0tcXVlcnklMjAlM0NzcGFuJTIwc3R5bGUlM0QlMjJjb2xvciUzQSUyM2U2ZGI3NCUyMiUzRSUyMlBhcmFtZXRlcnMlNUIlMkElNUQuJTdCVmFsdWUlM0FWYWx1ZSU3RCUyMiUzQyUyRnNwYW4lM0UlMjAlN0MlMjBncmVwJTIwVmFsdWUlMjAlN0MlMjBjdXQlMjAtZCUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzZTZkYjc0JTIyJTNFJTI3JTIyJTI3JTNDJTJGc3BhbiUzRSUyMC1mNCUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzNjZkOWVmJTIyJTNFJTI5JTNDJTJGc3BhbiUzRSUwQSUwQSUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzNzU3MTVlJTIyJTNFJTIzJTIzJTIzJTIzJTIzJTNDJTJGc3BhbiUzRSUwQSUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzNzU3MTVlJTIyJTNFJTIzJTIzJTIzJTIzJTIzJTIwUmVwbGFjZSUyMHRva2VucyUyMHdpdGglMjBhc3NpZ25lZCUyMHZhcmlhYmxlcyUzQyUyRnNwYW4lM0UlMEElM0NzcGFuJTIwc3R5bGUlM0QlMjJjb2xvciUzQSUyMzc1NzE1ZSUyMiUzRSUyMyUyMyUyMyUyMyUyMyUzQyUyRnNwYW4lM0UlMEElMEFzZWQlMjAtaSUyMCUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzZTZkYjc0JTIyJTNFJTIycyUyRnJkc191cmwlMkYlM0MlMkZzcGFuJTNFJTI0cmRzX3VybCUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzZTZkYjc0JTIyJTNFJTJGZyUyMiUzQyUyRnNwYW4lM0UlMjAlMkZob21lJTJGY2VudG9zJTJGYXV0b21hdGlvbiUyRnN0YW5kYWxvbmUueG1sJTBBJTBBJTNDc3BhbiUyMHN0eWxlJTNEJTIyY29sb3IlM0ElMjM2NmQ5ZWYlMjIlM0VpZiUzQyUyRnNwYW4lM0UlMjAlM0NzcGFuJTIwc3R5bGUlM0QlMjJjb2xvciUzQSUyM2Y5MjY3MiUyMiUzRSU1QiUzQyUyRnNwYW4lM0UlMjAteiUyMCUyNHJkczJfdXJsJTIwJTNDc3BhbiUyMHN0eWxlJTNEJTIyY29sb3IlM0ElMjNmOTI2NzIlMjIlM0UlNUQlM0MlMkZzcGFuJTNFJTBBJTNDc3BhbiUyMHN0eWxlJTNEJTIyY29sb3IlM0ElMjM2NmQ5ZWYlMjIlM0V0aGVuJTNDJTJGc3BhbiUzRSUwQSUyMHNlZCUyMC1pJTIwJTNDc3BhbiUyMHN0eWxlJTNEJTIyY29sb3IlM0ElMjNlNmRiNzQlMjIlM0UlMjJzJTJGcmRzMl91cmwlMkYlM0MlMkZzcGFuJTNFJTI0cmRzMl91cmwlM0NzcGFuJTIwc3R5bGUlM0QlMjJjb2xvciUzQSUyM2U2ZGI3NCUyMiUzRSUyRmclMjIlM0MlMkZzcGFuJTNFJTIwJTJGaG9tZSUyRmNlbnRvcyUyRmF1dG9tYXRpb24lMkZzdGFuZGFsb25lLnhtbCUwQSUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzNjZkOWVmJTIyJTNFZWxzZSUzQyUyRnNwYW4lM0UlMEElMjBzZWQlMjAtaSUyMCUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzZTZkYjc0JTIyJTNFJTIycyUyRnJkczJfdXJsJTJGJTNDJTJGc3BhbiUzRSUyNHJkc191cmwlM0NzcGFuJTIwc3R5bGUlM0QlMjJjb2xvciUzQSUyM2U2ZGI3NCUyMiUzRSUyRmclMjIlM0MlMkZzcGFuJTNFJTIwJTJGaG9tZSUyRmNlbnRvcyUyRmF1dG9tYXRpb24lMkZzdGFuZGFsb25lLnhtbCUwQSUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzNjZkOWVmJTIyJTNFZmklM0MlMkZzcGFuJTNFJTBBJTBBJTBBc2VkJTIwLWklMjAlM0NzcGFuJTIwc3R5bGUlM0QlMjJjb2xvciUzQSUyM2U2ZGI3NCUyMiUzRSUyMnMlMkZjb3JlX3VzZXJuYW1lJTJGJTNDJTJGc3BhbiUzRSUyNHJkc19jb3JlX3VzZXJuYW1lJTNDc3BhbiUyMHN0eWxlJTNEJTIyY29sb3IlM0ElMjNlNmRiNzQlMjIlM0UlMkZnJTIyJTNDJTJGc3BhbiUzRSUyMCUyRmhvbWUlMkZjZW50b3MlMkZhdXRvbWF0aW9uJTJGc3RhbmRhbG9uZS54bWwlMEFzZWQlMjAtaSUyMCUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzZTZkYjc0JTIyJTNFJTIycyUyRmNvcmVfcGFzc3dvcmQlMkYlM0MlMkZzcGFuJTNFJTI0cmRzX2NvcmVfcGFzc3dvcmQlM0NzcGFuJTIwc3R5bGUlM0QlMjJjb2xvciUzQSUyM2U2ZGI3NCUyMiUzRSUyRmclMjIlM0MlMkZzcGFuJTNFJTIwJTJGaG9tZSUyRmNlbnRvcyUyRmF1dG9tYXRpb24lMkZzdGFuZGFsb25lLnhtbCUwQSUzQ3NwYW4lMjBzdHlsZSUzRCUyMmNvbG9yJTNBJTIzZjkyNjcyJTIyJTNFJTdEJTNDJTJGc3BhbiUzRSUwQSUzQyUyRmNvZGUlM0UlM0MlMkZwcmUlM0UlM0MlMkZkaXYlM0U=
Next, we took a look at our startup scripts. We pass in several java arguments from JVM name, heap sizes, along with other various runtime values that can be unique depending on the role of the server or requirements. We updated the scripts with tokens and created another script to update those values and then start the application server.
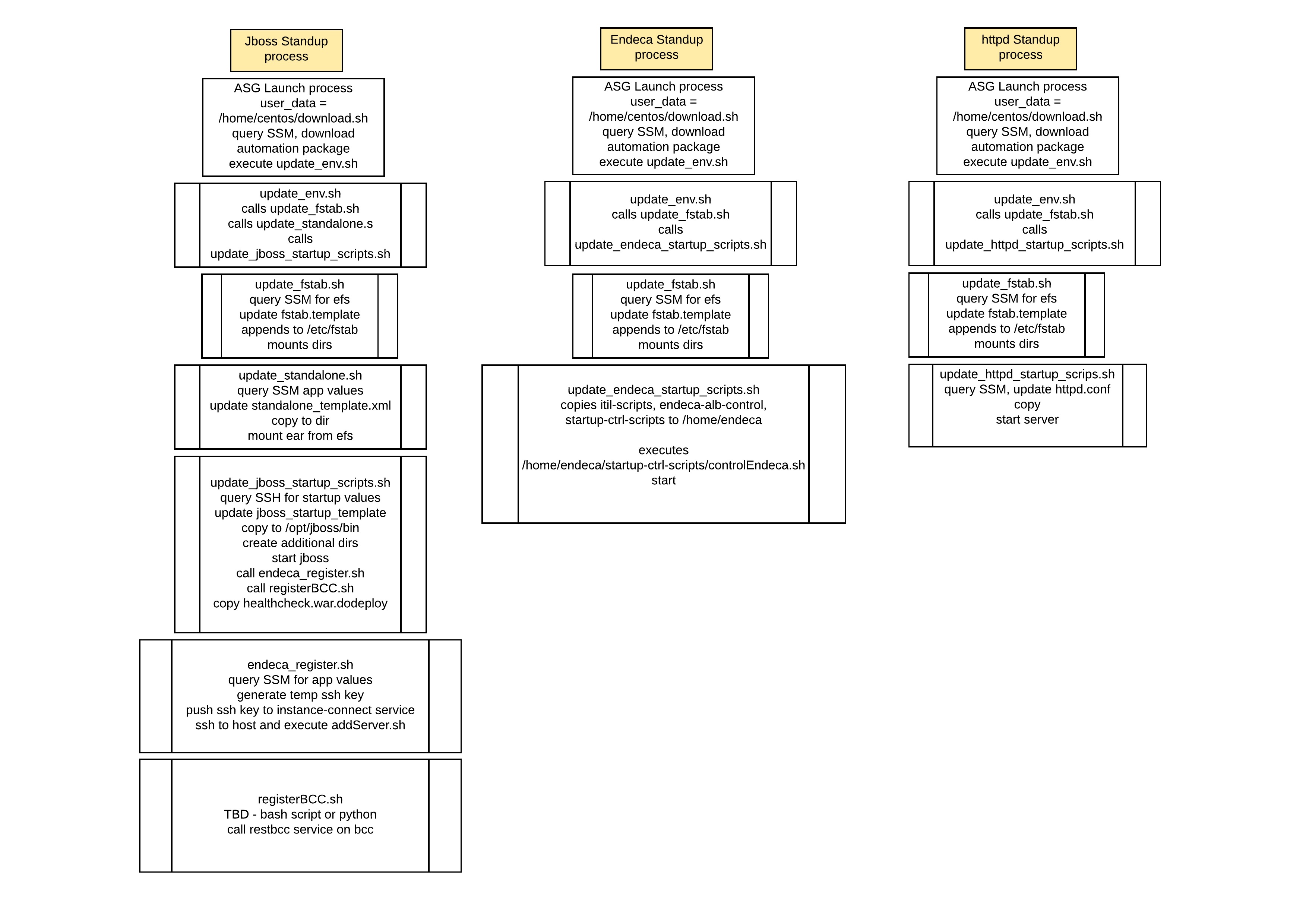
Once we had a viable image that was updating the required parameters and starting Jboss successfully we then had to start looking at solving the application requirements. This included registering with the ATG BCC and Endeca.
Oracle ATG had developed and promoted, as part of the Oracle IAAS toolset, a BCC rest service that when compiled into the ear would allow for external calls to register/deregister from the topology. We took that and developed a script that is called once JBoss is determined to be online and registers itself. We also developed scripts to add/remove an app server from the Endeca configuration files.
Once everything is up and running we register with the application load balancer for the client-facing apps which are called from the web tier.
All Things Terraform
Pivotree uses Terraform for IaC. Most of our cloud solutions have been built using Terraform. Terraform modules are either maintained internally or are in some cases internally approved community modules. We have several reference architectures depending on the platform and solution required
Using Terraform to stand up the environment was a matter of taking our reference architecture, updating it to leverage auto-scaling groups and a few other variables in our main configuration file. This would include anything we want to customize within the environment, EFS, RDS, EC2 instances, ASGs with EC2 info etc. We also developed a module to push any required values to SSM such as EFS endpoints, RDS URL and some server instances to load at runtime.
One of the challenges we realized early on was how to approach the patching/scaling events due to the way AWS manages instances provisioned by autoscaling groups. Terraform has no problems updating the launch configs but doesn’t do anything with that updated config. A solution we found was to use an open-source product called Bouncer which addresses this issue. We can call Bouncer from within Terraform and it will manage the scaling out of the ASG either in serial or canary mode. Our single instances in self-healing groups are all serial while our client-facing application servers are done canary to ensure it’s always available.
- The user_data was updated to reference the download.sh file we had built into our packer images. Once we had everything prepared it was a matter of executing our Terraform plan and approving it in Terraform Cloud.
As part of standing it all up, the ASG is configured to scale with parameters that trigger a scale-out at the appropriate threshold to give the new instance time to come online before the other servers are overwhelmed. ATG does require a little more time to come online and this has to be accounted for in the scaling thresholds.
Code Releases
With the infrastructure being immutable you no longer deploy applications to an instance and restart the application but rather deploy your code to an efs volume, update SSM with the path and using the AWS CLI you can execute the required changes on the ASG to launch new instances which will query SSM as part of its launch and symlink the appropriate package on the EFS volume.
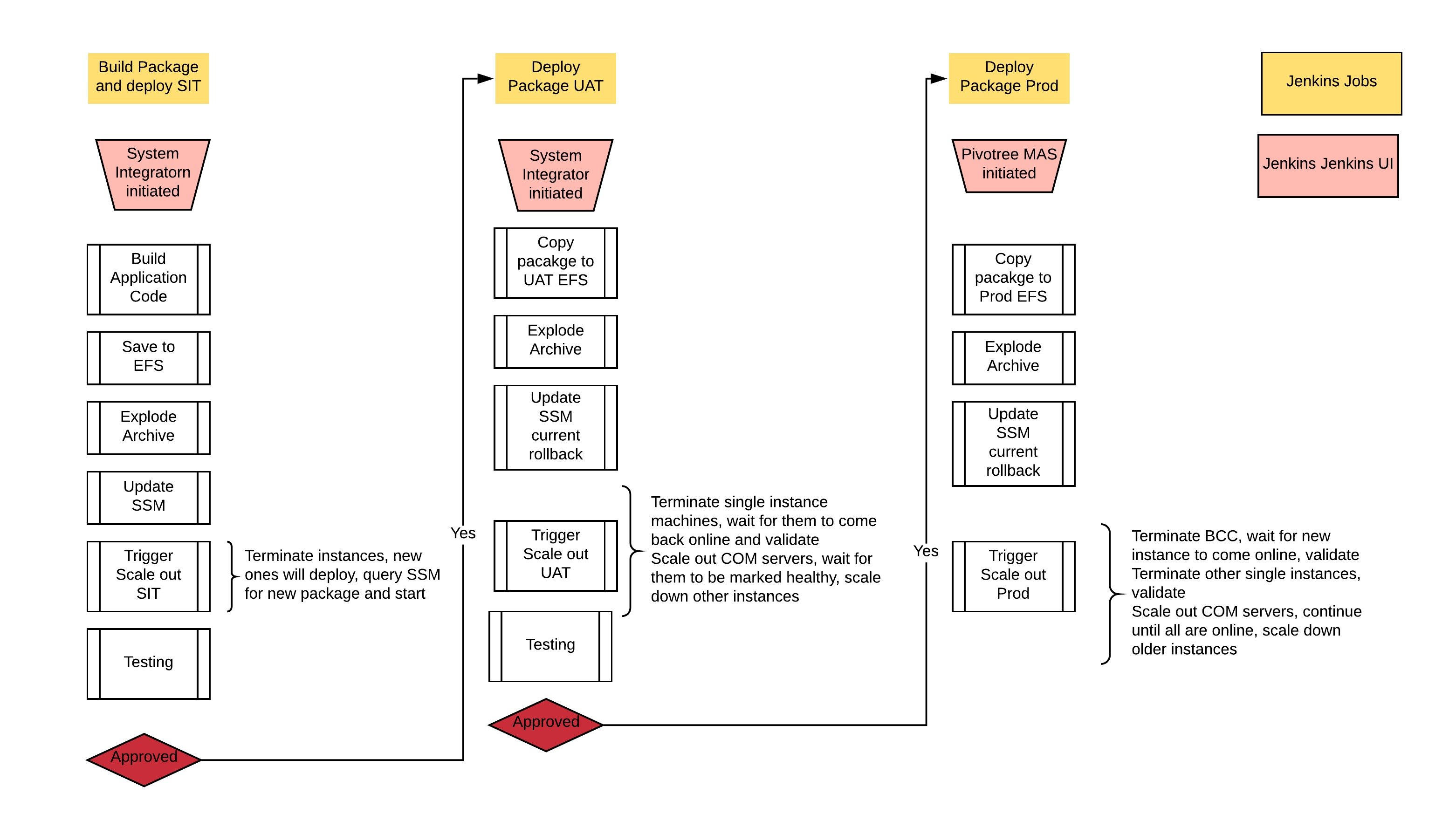
Additional Benefits
System Integrators and Operators no longer require access to the instances, all logging has been centralized within Cloudwatch. Direct ssh is no longer supported as we have enabled ec2-instance-connect and plan on migrating to AWS SSM Session Manager in the coming months. This helps address PCI requirements as well as simplifying the support experience.
With this solution in place, we developed a patching pipeline within Jenkins. First, we built the Packer package and placed the new AMI id into SSM. We have another job that will checkout our updated Terraform source code with the AMI ID of the new image, comments and commits the code back into git. This triggers a build in Terraform which we have decided for the time being is our gate and an operator has to approve the update. Once the operator approves the change, Terraform and Bouncer will complete it.
What’s Next?
Developing this solution we have given the client the ability to rapidly provision new environments, scale-out production on a demand basis without having additional servers laying around in wait and an improved patching process that reduces the risks and ensures a consistent image.
Over the next few months, we hope to extend this out so we can quickly turn a client onboarding around in a matter of days vs weeks or months. These are some of the areas we are looking at:
- Using Oracle RDS S3 integration we are building a solution to have a data pumped DB uploaded to a known space and then imported into the RDS instance.
- Working with the system integrator and client to further integrate the EAR configuration to improve the model even further.